【加速推理】分块并行解码
Created
Blockwise parallel decoding
来看一篇18年老文,和新近的LLM部署推理项目有关。
论文地址:https://arxiv.org/pdf/1811.03115.pdf
基础版
在原有模型基础上额外添加k个Lm headers,分别用来根据上文预测下文第i ∈ (1 ~ k)个token。这几个新header可以并行工作,因而几乎同时生成接下来1k个候选token。k个token的预测结果,同样可以利用预测下一个位置token的header并行计算每个位置生成结果的分布。
然而预测的位置越远,准确性就越低,为了保证生成质量需要一个验证步骤。回忆transformer模型的训练,由于我们提前知道完整的句子,所以可以实现并行,这里我们得到接下来1
那么最后一步就是对比辅助header 2 ~ k和header 1的结果,如果两者都认为预测token是使得句子概率最大的token则接受这个候选。
贪婪解码需要m次模型推理时间生成m个token,最优情况下该方法的用时为需要2m / k次。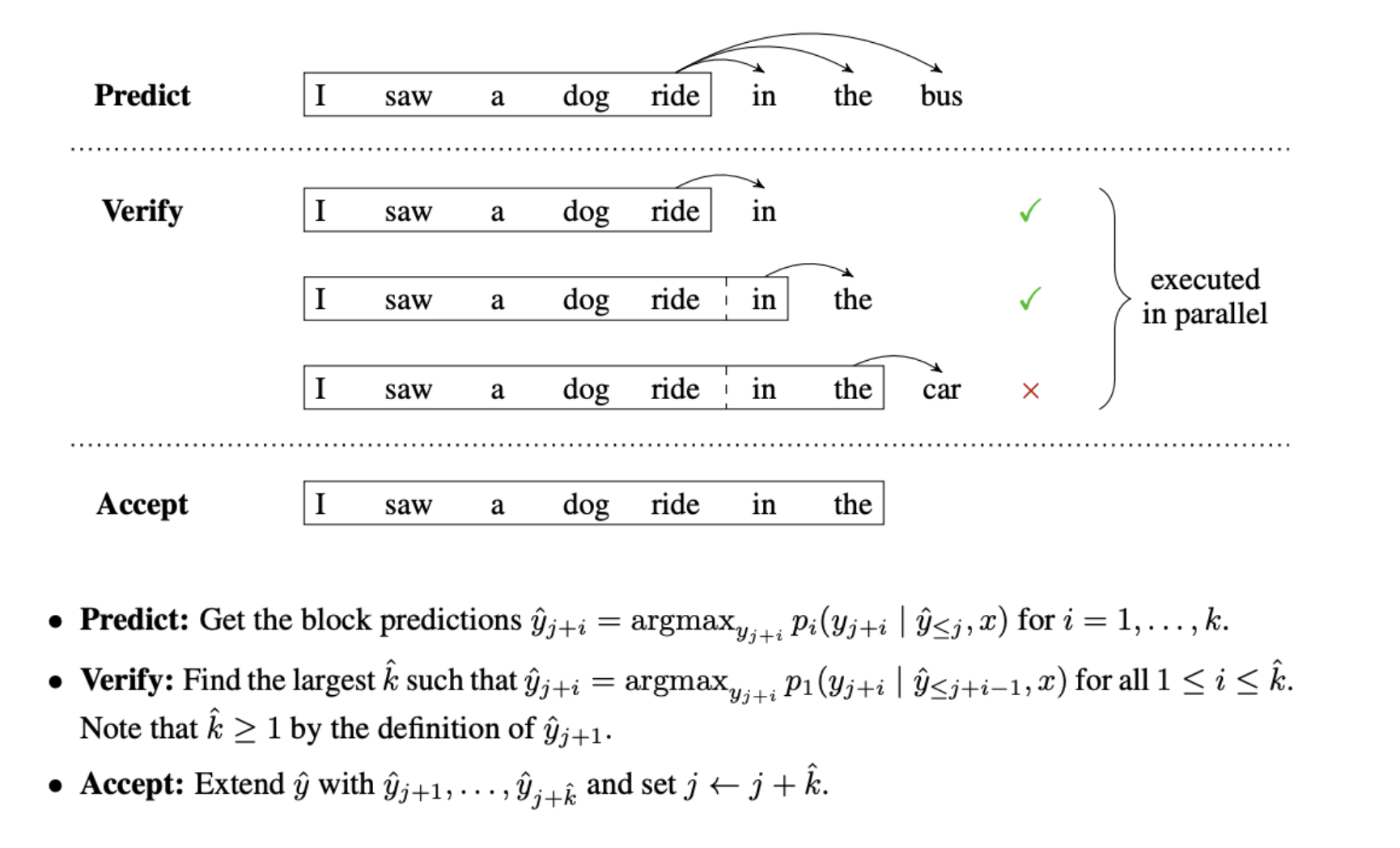
进阶版
进一步将 2m / k 优化到 m / k + 1。
回顾基础版,两次时间消耗分别用于预测和验证阶段,进阶版将验证和下一次的预测阶段合并。基础版验证时只有原始Lm header工作,进阶版在验证时所有header都要工作,同时完成这一步的验证和下一步的预测。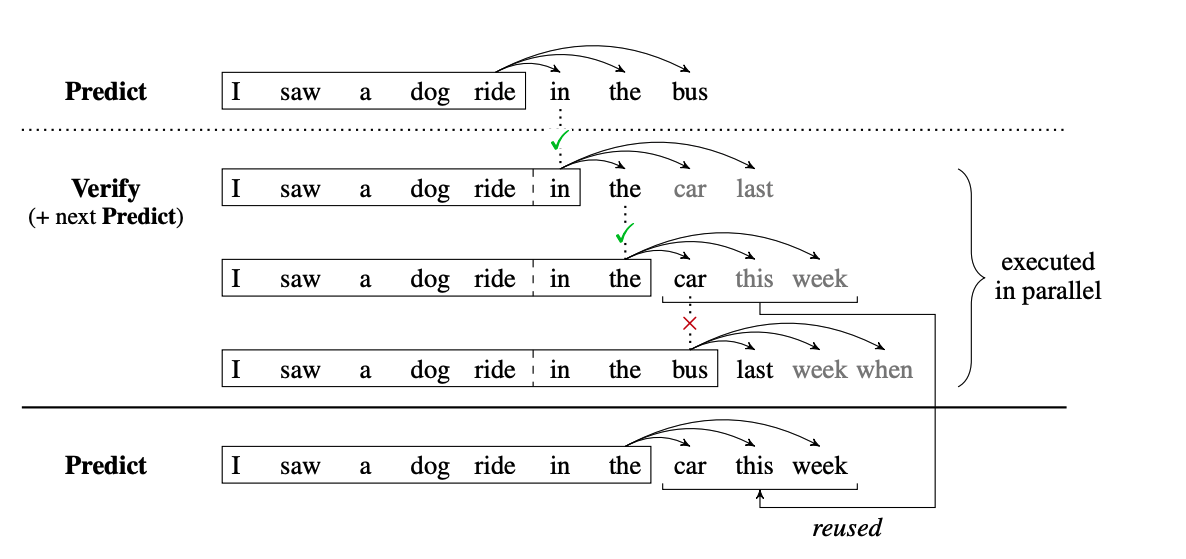
模型&实验
原论文在原始transformer output的基础上额外新增了1~k个新header,算loss的时候出于显存大小约束,没有取各header的平均值,而是每个mini batch随机选择一个header的结果作为loss。